Microsoft adds multi-model AI research system to M365 Copilot
Microsoft has introduced a new multi-model research capability in Microsoft 365 Copilot, combining multiple AI systems to generate, review, and refine complex research outputs in a single workflow.
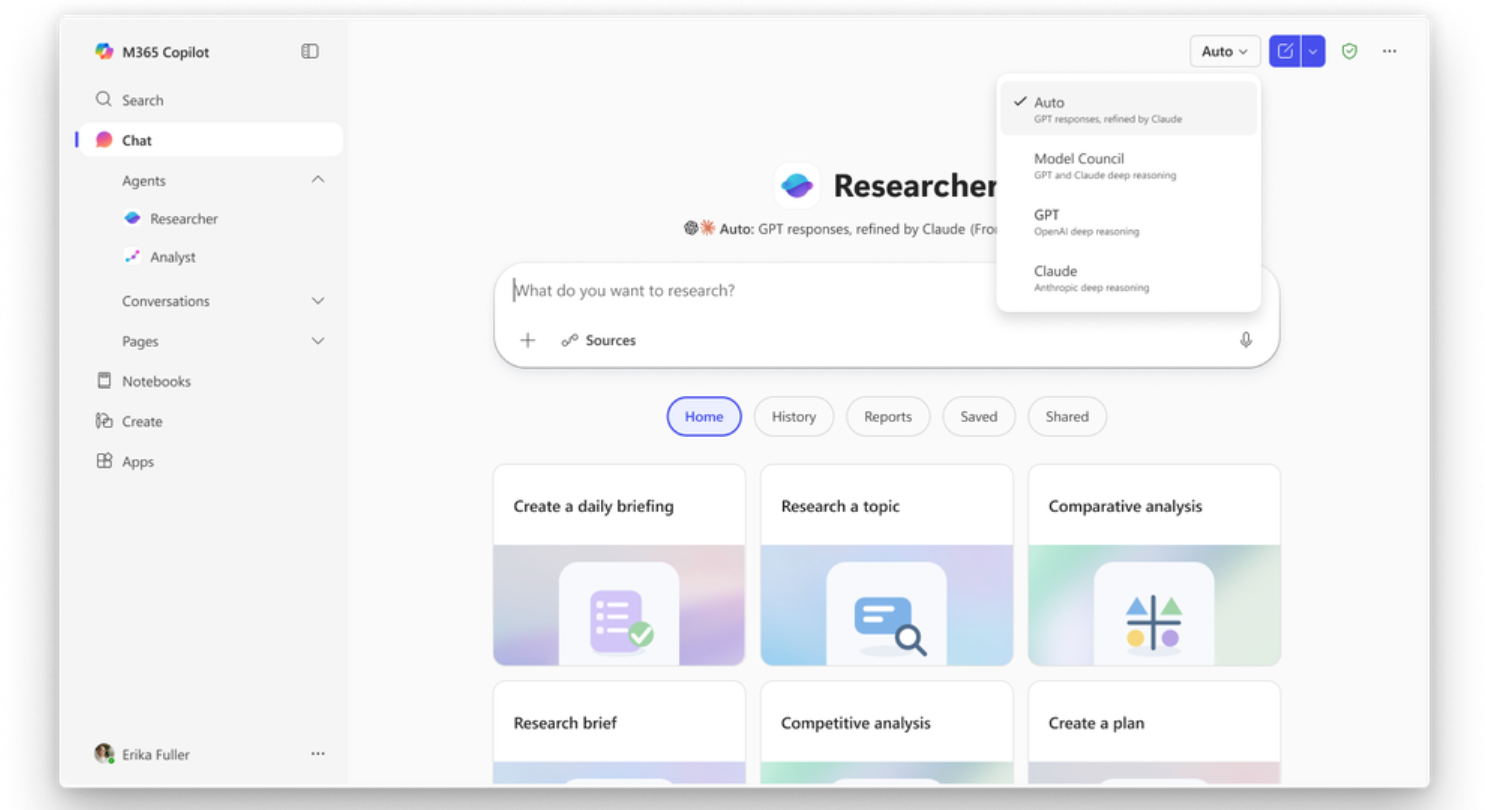
Microsoft has rolled out new multi-model capabilities within its Microsoft 365 Copilot Researcher tool, introducing systems called Critique and Council that combine multiple AI models to improve the quality and reliability of research outputs.
The update, highlighted by Microsoft Chairman and CEO Satya Nadella in a LinkedIn post, positions multi-model collaboration as the next step in enterprise AI, moving beyond single-model generation toward structured evaluation and comparison.
Nadella said: “Introducing Critique, a new multi-model deep research system in M365 Copilot. You can use multiple models together to generate optimal responses and reports.”
Critique introduces a dual-model architecture, where one model is responsible for generating research outputs and a second model reviews and refines them. The system separates planning, retrieval, and drafting from evaluation, creating a feedback loop designed to improve accuracy, structure, and completeness.
The review process is based on a structured framework, with the second model assessing source reliability, report completeness, and whether claims are grounded in verifiable evidence. Rather than rewriting content, the reviewer model focuses on strengthening the output while maintaining the original intent.
Microsoft said this approach differs from standard workflows where a single model handles all stages of research, which can limit consistency and depth.
Benchmark results show measurable gains
Microsoft evaluated the system using the DRACO benchmark, which measures deep research performance across 100 complex tasks spanning ten domains, including technology, medicine, and law.
Researcher with Critique recorded a +7.0 point improvement in overall performance, representing a 13.88 percent increase compared to the strongest system reported in the benchmark. Gains were recorded across all key areas, including factual accuracy, analytical depth, presentation quality, and citation quality.
The largest improvements were seen in breadth and depth of analysis, followed by presentation quality and factual accuracy. According to Microsoft, results were statistically significant across most domains, with eight out of ten showing measurable improvement.
The system also demonstrated stronger performance in identifying gaps in analysis, refining arguments, and improving the structure of final outputs, without increasing the volume of sources used.
Council introduces model comparison layer
Alongside Critique, Microsoft introduced Council, a parallel multi-model system designed to run different AI models side by side.
In this setup, separate models generate independent reports on the same task. A third model then evaluates the outputs, identifying where they agree, where they diverge, and what unique insights each contributes.
This comparison layer is designed to surface differences in interpretation, framing, and emphasis, giving users more visibility into how conclusions are formed.
Both Critique and Council are now available within Microsoft’s Frontier program, forming part of a broader push to embed advanced AI workflows directly into everyday work tools.
For enterprise users and EdTech providers, the shift toward multi-model systems signals a move toward more structured, auditable AI outputs, particularly in research-heavy tasks where accuracy, transparency, and evaluation are critical.