
One model to rule them all? Google DeepMind's Vision Banana outperforms specialized AI vision systems
A new technical report shows that one AI model can handle five different visual understanding tasks that previously required separate specialized systems, beating established benchmarks across segmentation, depth estimation, and surface normal prediction.
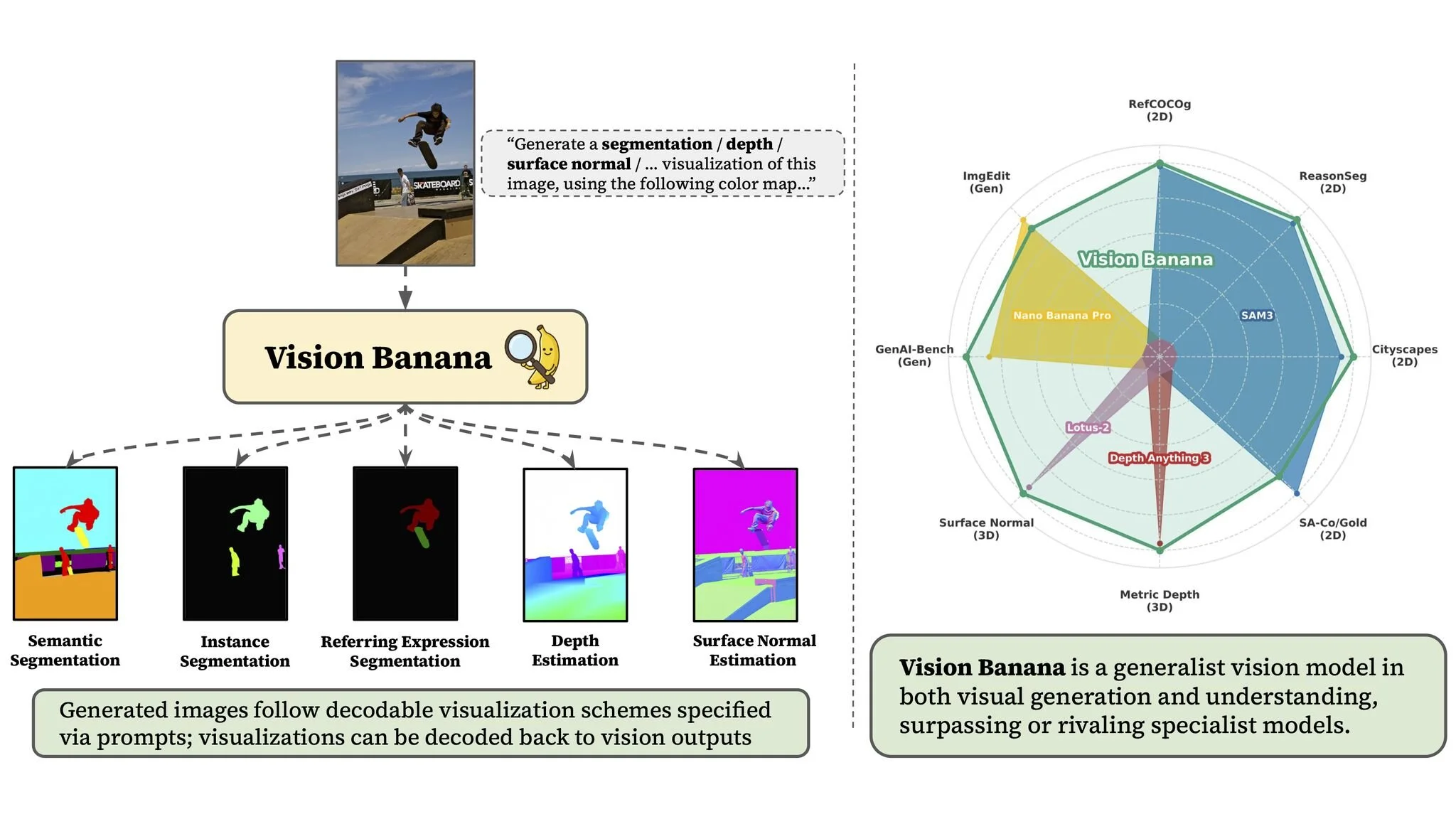
Vision Banana takes a single image and natural language prompt and generates visualization outputs across five vision tasks, outperforming or rivaling specialist models on each.
Google DeepMind has built a single AI model that can do the work of five specialized computer vision systems and beat most of them on their own turf. The model, called Vision Banana, is detailed in a new technical report published on arXiv and was demonstrated live at ICLR at Google's booth.
The central finding is straightforward: by taking an existing image generator, Nano Banana Pro, and instruction-tuning it with natural language prompts, the researchers created a unified model that can segment objects in images, estimate the depth of a scene from a single photo, predict the orientation of surfaces, and generate images, all with one set of weights and no specialized architecture. Previously, each of those tasks required its own purpose-built system.
Shangbang Long, Research Scientist at Google DeepMind and one of three equal-contribution project leads, shared the announcement on LinkedIn. He wrote: "We believe we are witnessing a paradigm shift for computer vision: Generative vision pretraining plays a foundational role similar to LLM pretraining. Image generation can serve as a universal interface for vision tasks, mirroring the role of text generation in language understanding and reasoning."
What Vision Banana can actually do
Vision Banana handles five categories of visual understanding through a single model. The simplest way to think about it is that a user provides an image and a natural language description of what they want the model to do, and Vision Banana generates a new image that visualizes the answer. That output can then be decoded into precise, measurable data.
In semantic segmentation, the model identifies and color-codes different types of objects in a scene, for example separating people from ocean from sky in a beach photograph. In instance segmentation, it goes further, distinguishing individual objects of the same type, such as coloring each piece of garlic in a photograph a different color so they can be counted and tracked separately.
In referring expression segmentation, Vision Banana can pick out specific objects described in natural language. A prompt like "the stretching cat is green, the cat cleaning itself is cyan" produces a segmentation map that correctly identifies and separates the two animals.
In monocular depth estimation, the model predicts how far away every part of a scene is from a single flat photograph, generating a color-mapped depth visualization. In surface normal estimation, it predicts which direction surfaces are facing across an image. Both of these 3D tasks are critical for robotics, augmented reality, autonomous vehicles, and increasingly for accessibility and spatial computing applications.
How it stacks up against the specialists
The results are measured under zero-shot transfer conditions, meaning Vision Banana was not specifically trained on the evaluation datasets. It is being tested cold, which makes the scores more impressive.
On segmentation, Vision Banana outperformed several established systems. On the Cityscapes benchmark, it scored 0.699 mIoU (a standard measure of segmentation accuracy), ahead of SAM 3 at 0.652 and X-Decoder at 0.520. On the ReasonSeg benchmark, which tests segmentation based on complex reasoning, Vision Banana paired with Gemini 2.5 Pro achieved the highest reported score of 0.793.
On 3D understanding, the results are equally strong. Averaged across six depth estimation benchmarks, Vision Banana achieved the top score of 0.882, ahead of UniK3D at 0.823 and Depth Pro at 0.715. On surface normal estimation averaged across three benchmarks, it recorded the lowest error rate of any system tested. Notably, Vision Banana does not use camera intrinsics, the technical information about the lens and sensor that most depth models rely on, making its accuracy all the more significant.
Why it matters beyond the benchmarks
The broader significance of the paper lies in what it suggests about the future direction of AI vision systems. Until now, the dominant approach in computer vision has been to build specialized models for specialized tasks. Vision Banana demonstrates that a single generative model, pretrained on image generation and then fine-tuned with natural language instructions, can match or beat those specialists across multiple domains.
The parallel Long draws with large language models is deliberate. Just as LLM pretraining on text generation turned out to be an effective foundation for reasoning, summarization, translation, and code generation, the paper argues that generative vision pretraining can serve as a universal foundation for visual understanding. If that holds, it could simplify the development of AI tools that process images in education, accessibility, content moderation, assessment, and beyond.
The research team spans 25 contributors at Google DeepMind, with the three project leads being Valentin Gabeur, Shangbang Long, and Songyou Peng. Leadership sponsors include Kaiming He, Saining Xie, and Thomas Funkhouser.





























