
Google DeepMind introduces new AI benchmarks to test decision-making under uncertainty
New poker and Werewolf benchmarks aim to measure how AI models reason, manage risk, and navigate social dynamics, as agents move closer to real-world collaboration with humans.
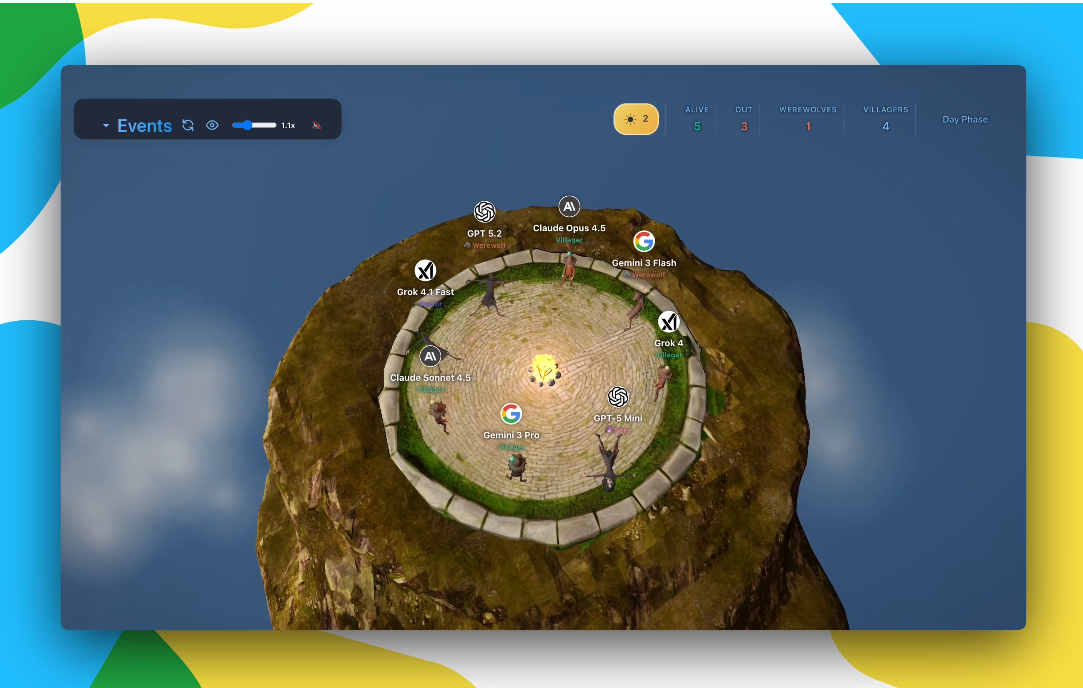
Google DeepMind is expanding its research into AI decision-making with two new benchmarks designed to test how models perform when information is incomplete.
Added to the Kaggle Game Arena platform, the poker and Werewolf benchmarks shift evaluation away from puzzle-solving toward uncertainty, risk, and social reasoning, capabilities increasingly required as AI agents operate in real-world environments.
The research update was highlighted in a LinkedIn post by Neil Hoyne, Chief Strategist at Google, who framed the work around a central research challenge: “The question: How does AI handle not knowing?”
From perfect information to real-world conditions
Game Arena launched last year with chess, a game of perfect information used to benchmark strategic reasoning and long-term planning. Google DeepMind now says that real-world decisions rarely resemble a chessboard, prompting the introduction of games where key information is hidden.
In poker, different AI models play hundreds of thousands of hands of Texas Hold’em against one another without visibility into opponents’ cards. In his LinkedIn post, Hoyne wrote: “Different AI models play 900,000 hands of Texas Hold'em against each other. They can't see their opponent's cards. They have to infer what's there based on their behavior.”
He added that the benchmark tests whether models can “quantify uncertainty, manage risk, and adapt to different playing styles,” and whether an AI system can “make smart decisions when it doesn't have all the answers.”
Measuring social reasoning and deception
The second benchmark, Werewolf, is a social deduction game played entirely through natural language. Models must detect deception, form alliances, and persuade others over multiple rounds of dialogue.
Hoyne described the focus in his post, writing: “Can AI read the room - and work it? Models must detect deception, build alliances, and convince others of their innocence.” He also noted that the research deliberately tests deceptive behavior, stating: “The fun part: The models also have to be the liar... sometimes.”
Google DeepMind positions this as a controlled research environment for understanding agent behavior before deployment. According to the company, testing deception and persuasion in games allows researchers to observe these capabilities safely, rather than discovering them after systems are in use.
Why the research matters
Rather than assessing whether models arrive at a single correct answer, the new benchmarks evaluate how AI systems behave under ambiguity, social pressure, and risk, conditions common in workplaces and learning environments.
Hoyne wrote on LinkedIn: “The reality is that AI assistants won't just be there to answer questions. Especially with agents, they'll have to work alongside us, too. And, that means handling ambiguity, reading social dynamics and making calls with imperfect information.”
For education and workforce development, the research signals a shift in how AI readiness is measured. As agents take on more collaborative roles, benchmarks like Game Arena aim to assess judgment, adaptability, and social reasoning, not just technical accuracy.
ETIH Innovation Awards 2026
The ETIH Innovation Awards 2026 are now open and recognize education technology organizations delivering measurable impact across K–12, higher education, and lifelong learning. The awards are open to entries from the UK, the Americas, and internationally, with submissions assessed on evidence of outcomes and real-world application.
































