OpenAI's GPT-5.5 sets new benchmarks in agentic coding, scientific research, and computer use
The model arrives with state-of-the-art scores on coding and computer use benchmarks, a million-token API context window, and tighter controls on cybersecurity use.
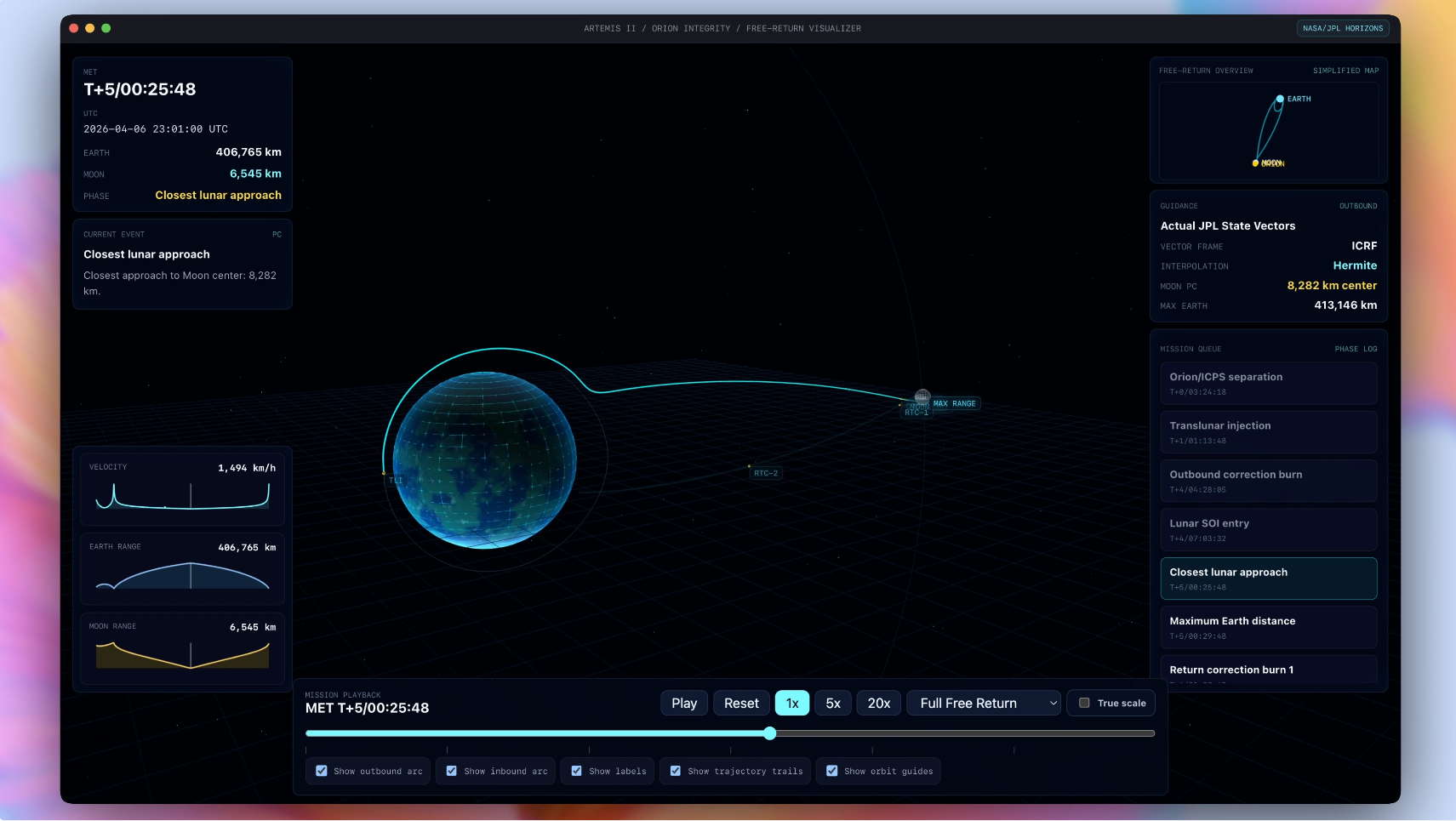
A 3D Artemis II free-return mission visualizer built in OpenAI Codex using GPT-5.5, rendering orbital trajectories from NASA/JPL Horizons vector data for Orion, the Moon, and the Sun. The app was generated from a single prompt and image reference.
OpenAI has released GPT-5.5, claiming state-of-the-art performance across agentic coding, computer use, knowledge work, and scientific research benchmarks, alongside what the company describes as a significant reduction in token consumption compared with GPT-5.4.
The model is rolling out to Plus, Pro, Business, and Enterprise users in ChatGPT and Codex, with GPT-5.5 Pro available to Pro, Business, and Enterprise users. API access is expected to follow, priced at $5 per one million input tokens and $30 per one million output tokens, with a one million token context window.
Benchmark gains span coding, computer use, and research
On Terminal-Bench 2.0, which tests complex command-line workflows requiring planning and tool coordination, GPT-5.5 scores 82.7 percent, up from 75.1 percent for GPT-5.4. On SWE-Bench Pro, a benchmark built around real-world GitHub issue resolution, the model reaches 58.6 percent. On OSWorld-Verified, which measures whether a model can operate real computer environments on its own, it scores 78.7 percent.
The company also reports gains on scientific research benchmarks. GPT-5.5 scores 80.5 percent on BixBench, a bioinformatics and data analysis evaluation, up from 74.0 percent for GPT-5.4. On GeneBench, a new evaluation focused on multi-stage scientific data analysis in genetics and quantitative biology, the model scores 25.0 percent. OpenAI states that tasks on GeneBench often correspond to multi-day projects for scientific experts.
OpenAI says model uses fewer tokens to complete comparable work
One of the more commercially significant claims is that GPT-5.5 reaches higher-quality outputs with fewer tokens than GPT-5.4 and matches its predecessor's per-token latency in real-world serving. On Terminal-Bench 2.0, Expert-SWE, and Tau2-bench Telecom, the company reports GPT-5.5 outperforming GPT-5.4 while consuming fewer output tokens.
The efficiency claim matters for developers and enterprise customers calculating per-task cost. While GPT-5.5 carries a higher per-token rate in the API than GPT-5.4, lower token consumption per task could offset that increase depending on workload. Batch and Flex pricing are available at half the standard API rate.
Stronger cybersecurity safeguards arrive alongside capability gains
OpenAI has classified GPT-5.5's cybersecurity and biological capabilities as High under its Preparedness Framework, though below the Critical threshold. The company reports 81.8 percent on CyberGym, an internal cybersecurity benchmark, up from 79.0 percent for GPT-5.4, and 88.1 percent on internal Capture-the-Flag challenge tasks.
In response, OpenAI has deployed what it calls stricter classifiers for high-risk cybersecurity requests and added protections against repeated misuse, acknowledging that "some users may find them annoying initially." The company is also running a Trusted Access for Cyber program through Codex, offering verified users expanded access to the model's advanced security capabilities. Organizations responsible for defending critical infrastructure can apply for access to cyber-permissive variants, including GPT-5.4-Cyber, subject to security requirements.
Early partners report sharper reasoning and longer task persistence
Michael Truell, co-founder and CEO at Cursor, says: "GPT-5.5 is noticeably smarter and more persistent than GPT-5.4, with stronger coding performance and more reliable tool use. It stays on task for significantly longer without stopping early, which matters most for the complex, long-running work our users delegate to Cursor."
Justin Boitano, VP of Enterprise AI at NVIDIA, says: "GPT-5.5 delivers the sustained performance required for execution-heavy work. Built and served on NVIDIA GB200 NVL72 systems, the model enables our teams to ship end-to-end features from natural language prompts, cut debug time from days to hours, and turn weeks of experimentation into overnight progress in complex codebases. It's more than faster coding—it's a new way of working that helps people operate at a fundamentally different speed."
Dan Shipper, Founder and CEO of Every, reportedly describes GPT-5.5 as "the first coding model I've used that has serious conceptual clarity."
Model contributed to serving infrastructure and a new mathematical proof
OpenAI states that GPT-5.5 was co-designed with NVIDIA GB200 and GB300 NVL72 systems and says Codex and earlier versions of the model contributed to improvements in the serving stack itself. The company reports that Codex analyzed weeks of production traffic data and wrote custom heuristic algorithms for load balancing and partitioning, resulting in a more than 20 percent increase in token generation speeds.
OpenAI also reports that an internal version of GPT-5.5 with a custom harness contributed to a new proof about off-diagonal Ramsey numbers, a problem area in combinatorics. The proof was subsequently verified in Lean, a formal proof verification system.
API availability remains pending as OpenAI finalizes safeguards
GPT-5.5 and GPT-5.5 Pro will be available through the Responses and Chat Completions APIs, though OpenAI has not set a firm date beyond saying the release will follow "very soon." The company says API deployments require different safeguards than ChatGPT and Codex, and that it is working with partners and customers on safety and security requirements for serving the model at scale. GPT-5.5 Pro in the API will be priced at $30 per one million input tokens and $180 per one million output tokens, with Priority processing available at 2.5 times the standard rate.